This article explores a seq2seq architecture for solving simple probability problems in Saxton et. al.’s Mathematics Dataset. A transformer is used to map questions to intermediate steps, while an external symbolic calculator evaluates intermediate expressions. This approach emulates how a student might solve math problems, by setting up intermediate equations, using a calculator to solve them, and using those results to construct further equations.
Table of Contents
A few months ago, DeepMind released Mathematics Dataset, a codebase for procedurally generating pairs of mathematics questions and answers, to serve as a benchmark for the ability of modern neural architectures to learn mathematical reasoning.
The data consists of a wide variety of categories, ranging from basic arithmetic to probability. Here’s an example question-answer pair from the paper:
Question:
What is g(h(f(x))), where f(x) = 2x + 3, g(x) = 7x − 4, and h(x) = −5x − 8?
Answer:
−70x − 165
Both questions and answers are in the form of free-form text, making seq2seq models a natural first step for solving this dataset. In fact, the paper by Saxton et. al. released alongside the dataset includes baseline performance metrics for today’s state-of-the-art seq2seq models, applied naively to the dataset.
For more details, I highly recommend reading the accompanying paper by Saxton et. al..
Solving simple probability problems
In this article, we focus on the dataset categories relating to probability: swr_p_level_set and swr_p_sequence.
swr_p_level_set contains questions for calculating the probability of obtaining certain counts of letters.
QUESTION: Two letters picked without replacement from {v: 3, q: 1, x: 1, o: 1}. What is prob of picking 1 x and 1 v?
ANSWER: 1/5
swr_p_sequence contains questions for calculating the probability of a particular sequence of letters.
QUESTION: Calculate prob of sequence ko when two letters picked without replacement from yyyykkoykkyoyyokyyy.
ANSWER: 5/114
In the baseline approach used by Saxton et. al., the model takes in the question as a sequence of characters, and tries to directly map that to another sequence of characters, representing the correct probability. A vanilla transformer architecture does surprisingly well, with accuracies of ~0.77 and ~0.73 on the swr_p_level_set and swr_p_sequence test sets, respectively.
Humans use intermediate steps to solve math problems
To solve the same problems, a human goes through a series of reasoning and intermediate steps, similar to the following:
QUESTION: Calculate prob of sequence ko when two letters picked without replacement from yyyykkoykkyoyyokyyy.
*Count the total number of letters in yyyykkoykkyoyyokyyy* -> 19
*Count the number of specific letters needed* -> k: 5 counts, o: 3 counts
*Set up the equation for solving probability of the sequence ko* -> 5/19 * 3/18
*Solve the equation (manually or using a calculator)* -> 5/19 * 3/18 = 5/114
ANSWER: 5/114
This insight naturally leads to the following question: Instead of training the network on question-answer pairs, can we use intermediate steps to provide a better signal for the model to learn from? Presumably, a network will find it easier to capture the structure between intermediate steps, rather than the more complex structure between a question and its answer.
Humans can use calculators for tedious work
The final intermediate step above 5/19 * 3/18 = 5/114 involves a multiplication between two fractions. While this specific equation is fairly simple and can be solved manually by a human in a few seconds, we can easily imagine questions about probability to involve more complicated fractions e.g. (23/543 * 34/2551 * 673/12043) * (25!) / (20! * 19!). In probability (and many other tasks), human “intelligence” is mostly used to put together the appropriate equations. Calculators were invented to do the tedious work of actually evaluating them.
While we can try forcing a neural network to figure out how to work through tedious intermediate calculations on its own, we can make its task much simpler by instead giving it access to an external symbolic calculator. This way, the network can focus on learning how to solve a problem, outsourcing tedious calculations elsewhere.
Methodology
How do we integrate the above two insights (intermediate steps and external calculator) with our baseline seq2seq models?
Generating intermediate steps
To generate intermediate steps, we modify the Mathematics Dataset generation code to procedurally generate question-intermediate step (IS) pairs, instead of the original question-answer pairs. A question-IS pair for swr_p_sequence looks like the following:
QUESTION:
Calculate prob of sequence jppx when four letters picked without replacement from {x: 3, j: 1, p: 5}.
INTERMEDIATE STEPS:
x:3 j:1 p:5
3+1+5=9
(1/9)*(5/8)*(4/7)*(3/6)=5/252
5/252
For swr_p_level_set:
QUESTION:
Calculate prob of picking 2 b and 2 d when four letters picked without replacement from dbbbjbbd.
INTERMEDIATE STEPS:
d:2 b:5 j:1
2+5+1=8
(2/8)*(1/7)*(5/6)*(4/5)=1/42
4!/(2!*2!)=6
6*1/42=1/7
1/7
The intermediate steps for both categories follow roughly the same pattern, with a few extra steps for swr_p_level_set:
- Count the number of instances for each letter.
d:2 b:5 j:1 - Sum together the counts, to get the total number of letters.
2+5+1=8 - Set up the equation for calculating the probability of a sequence using the product rule for probability.
(2/8)*(1/7)*(5/6)*(4/5)=1/42 - (For
swr_p_level_set) Set up an equation for calculating the unique number of permutations of sampled letters.4!/(2!*2!)=6 - (For
swr_p_level_set) Multiply together the results of step 3 and step 4.6*1/42=1/7 - The last line always contains the final answer.
1/7
A few special cases occur in some problems, namely questions that lead to a probability of 1 (events guaranteed to happen) or 0 (impossible events). These cases are fairly trivial and easy for a human to spot, and we omit intermediate steps for these questions:
QUESTION: Four letters picked without replacement from {s: 8}. Give prob of sequence ssss.
ANSWER: 1
QUESTION: Four letters picked without replacement from miafjh. Give prob of sequence ajaf.
ANSWER: 0
We can directly use this new dataset as an input-output (question-IS) pair for a seq2seq model.
Decoding with an external symbolic solver
As our external symbolic calculator, we’ll use SymPy, “a Python library for symbolic mathematics”. SymPy is both incredibly powerful and intuitive. For our purposes, we’ll need only a single function from SymPy, sympy.parsing.sympy_parser.parse_expr. parse_expr reads in a Python string, parses it as a symbolic math expression, and simplifies it as much as possible. Here’s an example of it in action:
>>> from sympy.parsing.sympy_parser import parse_expr
>>> str(parse_expr("2/3 + 5/9 + 32/527"))
6085/4743
>>> str(parse_expr("5! / (3!*2!)"))
10
>>> str(parse_expr("not a valid expression"))
SyntaxError: invalid syntax
Powerful stuff. parse_expr can handle all kinds of operations, and is more than enough for solving intermediate steps for simple probability questions.
How do we integrate our symbolic solver with a neural network? Consider how a transformer-based seq2seq decoder generates each character of the output. If you’re unfamiliar with transformers or need a review, check out this excellent article from Jay Alammar, The Illustrated Transformer.
During decoding, the decoder outputs a single character per time step. At each time step, the decoder takes two inputs:
- The output vector from the encoder, which encodes the input question. This is used to condition the decoder for all time steps.
- The decoder output so far. e.g. if the decoder output up to the current time step is
2 + 2 =, this is fed back to the decoder as an input for predicting the next character (perhaps a4).
This gives us a very natural way to integrate our SymPy calculator into the decoding process of a transformer:
- Decode as normal, while waiting for an
=sign. - After decoding an
=sign, take the last expression before the=sign, and run it throughparse_expr. parse_expr’s string output is appended to the decoder’s “output so far”. This means it is treated by the decoder as any other previous output token, and will be used to predict the rest of the characters.- Repeat steps 1-3 until the end-of-sentence symbol is predicted.
The animation below illustrates the decoding process.
To use a human metaphor, this is akin to a student punching keys into a calculator, writing down the result, and figuring out next steps based on the calculator’s output.
Training with an external symbolic solver
Decoding is very natural, but how do we train the network?
For a regular seq2seq task, the training data comes in the form of input-target pairs of sequences, and the loss function is calculated based on how well the decoder output matches the target sequence 1.
The input sequence is passed through the encoder, while the target sequence is used to (1) calculate the loss function of the network, and (2) right-shifted by one to be used as the decoder input.
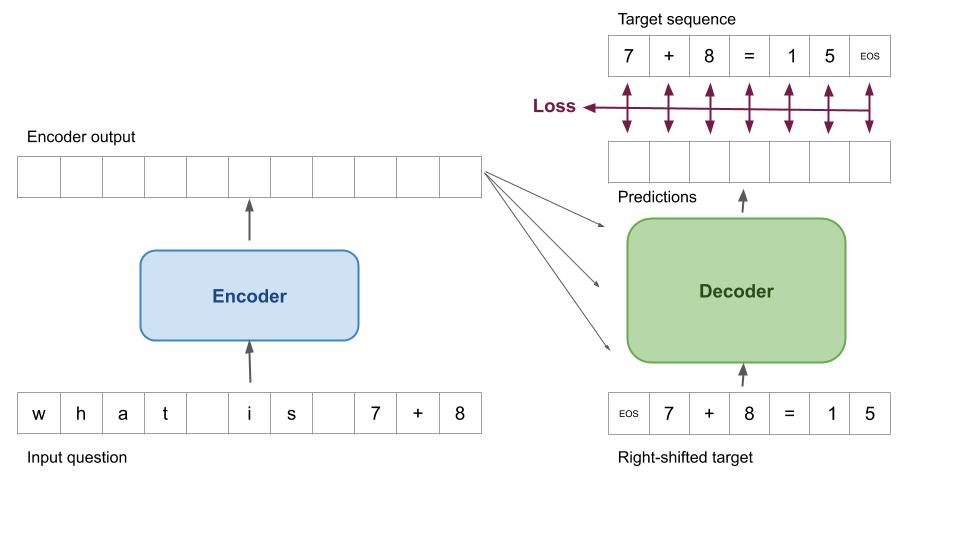
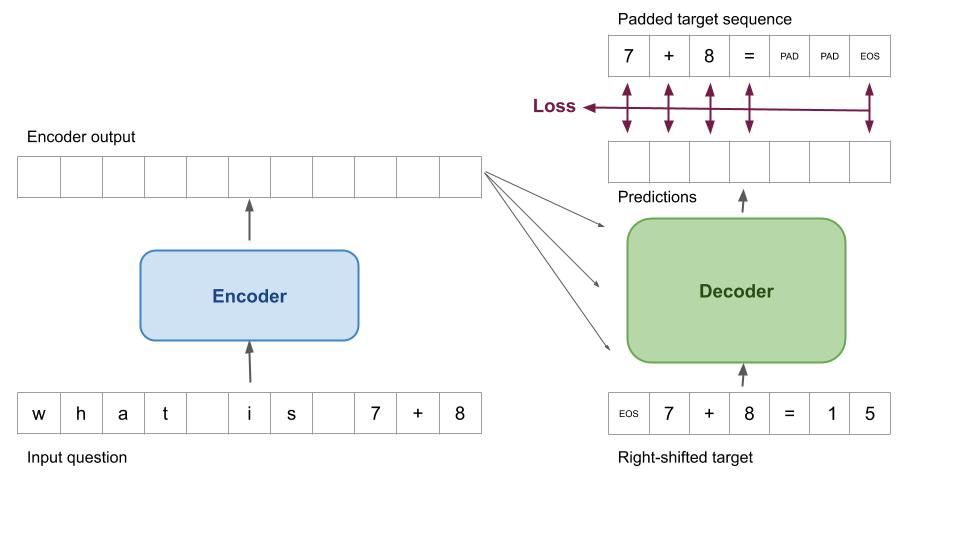
For seq2seq with a symbolic solver, the loss function must instead capture how well the decoder output matches the target sequence, except at positions the solver is expected to fill.
In our implementation, our training data now consists of three sequences: input, target, and masked target. The masked target sequence is a copy of the target sequence, where tokens to be filled in by the solver are replaced by a special masking symbol 2.
The computation graph for training is shown in the figure below. The main difference from the original seq2seq training procedure is that the masked target sequence is used to calculate the loss function. The special masking symbols signify that the decoder outputs at these positions must not contribute to the loss function 3. In other words, we don’t care what the network outputs are at those positions, since they will be overwritten by the symbolic solver’s output.
Experiment details
Experiment details are mostly based on Saxton et. al.’s baseline implementations, with a few differences to reduce computational resource requirements 4.
- The dataset used is a combination of the
swr_p_level_setandswr_p_sequencetraining sets with intermediate steps, for a total of 2 million samples in the training set. - To quantify the effect of intermediate steps vs the use of a symbolic solver, we train two networks: one using a transformer to directly map from question to intermediate steps, and another using a transformer + external symbolic solver to evaluate intermediate expressions.
- We measure a network’s performance on two test sets: an interpolated test set, and an extrapolated test set 5, each with 1000 samples. Accuracy is based solely on the final answer, not the network-generated intermediate steps.
- We use a batch size of about ~160 on a single free GPU, trained with 150k steps.
- Greedy decoding 6 is used to generate predictions.
Results and Analysis
The following table shows accuracy results on the swr_p_level_set and swr_p_sequence interpolation and extrapolation test sets.
| p_level_set (interpolation) | p_sequence (interpolation) | p_level_set (extrapolation) | p_sequence (extrapolation) | |
|---|---|---|---|---|
| Transformer baseline (Saxton et. al.) 7 | ~0.77 | ~0.73 | ~0.057 | ~0.045 |
| Transformer with intermediate steps | 0.701 | 0.675 | 0.074 | 0.065 |
| Transformer with intermediate steps and symbolic calculator | 0.997 | 0.997 | 0.055 | 0.058 |
Interpolation test set performance insights
The results for the transformer-calculator hybrid show a clear improvement over the baseline on the interpolated test set, and in fact scores almost perfectly on both swr_p_level_set and swr_p_sequence. This shows how easy the underlying task actually is when the network does not need to learn to accurately evaluate intermediate steps.
Since the results are only almost perfect, it’s interesting to view the failure cases for the network.
Failure cases for swr_p_level_set:
[QUESTION] Calculate_prob_of_picking_1_o_and_3_l_when_four_letters_picked_without_replacement_from_{o:_7,_l:_13}.
[TARGET ANSWER] o:7 l:13 7+13=20 (7/20)*(13/19)*(12/18)*(11/17)=1001/9690 4!/(3!)=4 4*1001/9690=2002/4845 2002/4845
[PREDICTION] o:7 l:13 7+13=20 (7/20)*(13/19)*(12/18)*(11/17)=1001/9690 4!/(3!)=4 4*101/9690=202/4845 202/4845
[QUESTION] What_is_prob_of_picking_1_v,_1_g_and_1_a_when_three_letters_picked_without_replacement_from_gaagggaagaaavgaavaav?
[TARGET ANSWER] g:6 a:11 v:3 6+11+3=20 (6/20)*(11/19)*(3/18)=11/380 3!=6 6*11/380=33/190 33/190
[PREDICTION] a:10 g:6 v:3 10+6+3=19 (10/19)*(6/18)*(3/17)=10/323 3!=6 6*10/323=60/323 60/323
[QUESTION] Two_letters_picked_without_replacement_from_kk._What_is_prob_of_picking_2_k?
[TARGET ANSWER] 1
[PREDICTION] k:2 h:1 2+1=3 (2/3)*(1/2)=1/3 1/3
Failure cases for swr_p_sequence:
[QUESTION] Calculate_prob_of_sequence_ujh_when_three_letters_picked_without_replacement_from_hiuuuouuueoojuu.
[TARGET ANSWER] o:3 h:1 j:1 e:1 i:1 u:8 3+1+1+1+1+8=15 (8/15)*(1/14)*(1/13)=4/1365 4/1365
[PREDICTION] o:3 h:1 u:8 i:1 e:1 3+1+8+1+1=14 (8/14)*(1/13)*(1/12)=1/273 1/273
[QUESTION] Four_letters_picked_without_replacement_from_ababaababbbbaaaaaaaa._What_is_prob_of_sequence_abaa?
[TARGET ANSWER] b:7 a:13 7+13=20 (13/20)*(7/19)*(12/18)*(11/17)=1001/9690 1001/9690
[PREDICTION] b:7 a:12 7+12=19 (12/19)*(7/18)*(11/17)*(10/16)=385/3876 385/3876
[QUESTION] Calculate_prob_of_sequence_gq_when_two_letters_picked_without_replacement_from_{q:_1,_g:_1}.
[TARGET ANSWER] q:1 g:1 1+1=2 (1/2)*(1/1)=1/2 1/2
[PREDICTION] q:1 g:1 1+1=2 (1/2)*(1/10)=1/20 1/20
One failure case seems to be when the network makes a mistake in counting the number of letters. This happens in long sequences, and the network is usually off by 1 on the letter with the highest count.
Other failure cases are when the network fails to recognize that the event is impossible (0 probability), or simply failing to set up the correct intermediate expressions.
Extrapolation test set performance insights
The original baseline from Saxton et. al. scores poorly on the extrapolated test set, and the networks trained in this article do no better, measuring <6% accuracy on questions that sample more letters than seen during training.
Let’s take a look at a few failure cases:
[QUESTION] What_is_prob_of_picking_1_d,_1_s_and_3_g_when_five_letters_picked_without_replacement_from_gggggggsggdgggg?
[TARGET ANSWER] d:1 s:1 g:13 1+1+13=15 (1/15)*(1/14)*(13/13)*(12/12)*(11/11)=1/210 5!/(3!)=20 20*1/210=2/21 2/21
[PREDICTION] s:1 d:1 g:13 1+1+13=15 (1/15)*(13/14)*(12/13)=2/35 3!/(3!)=1 1/35
[QUESTION] Five_letters_picked_without_replacement_from_nntdgadgggaadgtgddrg._What_is_prob_of_picking_1_t,_1_r,_1_g_and_2_d?
[TARGET ANSWER] n:2 g:7 d:5 t:2 a:3 r:1 2+7+5+2+3+1=20 (7/20)*(5/19)*(4/18)*(2/17)*(1/16)=7/46512 5!/(2!)=60 60*7/46512=35/3876 35/3876
[PREDICTION] d:5 a:3 g:7 r:1 n:2 t:2 5+3+7+1+2+2=20 (5/20)*(7/19)*(1/18)=7/1368 3!/(2!)=3 3*7/1368=7/456 7/456
[QUESTION] What_is_prob_of_sequence_inrir_when_five_letters_picked_without_replacement_from_{n:_1,_i:_4,_r:_2}?
[TARGET ANSWER] n:1 i:4 r:2 1+4+2=7 (4/7)*(1/6)*(2/5)*(3/4)*(1/3)=1/105 1/105
[PREDICTION] n:1 i:4 r:2 1+4+2=7 (4/7)*(1/6)*(2/5)=4/105 4/105
[QUESTION] Calculate_prob_of_sequence_yavay_when_five_letters_picked_without_replacement_from_yvaaaayyaayvavy.
[TARGET ANSWER] v:3 y:5 a:7 3+5+7=15 (5/15)*(7/14)*(3/13)*(6/12)*(4/11)=1/143 1/143
[PREDICTION] v:3 y:5 a:7 3+5+7=15 (5/15)*(7/14)*(3/13)=1/26 1/26
While the network is still able to properly count letters (letter counts are not extrapolated and follow the same distribution as the training set), it completely fails to set up the correct equations using the probability product rule, not realizing that it’s possible for these equations to have more than 4 factors.
Perhaps this result is unsurprising, as we did not explicitly design the network to handle this sort of out-of-distribution generalization. We argue, however, that this does not diminish the shown benefits of an external solver. An architecture explicitly designed to generalize to OOD samples is just as likely to benefit from not needing to evaluate intermediate expressions by itself.
Let’s take a look at a sample of extrapolated questions the network did get right.
[QUESTION] What_is_prob_of_sequence_jzttj_when_five_letters_picked_without_replacement_from_zjrrtpjjjv?
[TARGET ANSWER] 0
[PREDICTION] 0
[QUESTION] What_is_prob_of_sequence_ccccc_when_five_letters_picked_without_replacement_from_ccccccccc?
[TARGET ANSWER] 1
[PREDICTION] 1
[QUESTION] Five_letters_picked_without_replacement_from_{c:_1,_z:_7}._What_is_prob_of_sequence_zczzz?
[TARGET ANSWER] c:1 z:7 1+7=8 (7/8)*(1/7)*(6/6)*(5/5)*(4/4)=1/8 1/8
[PREDICTION] c:1 z:7 1+7=8 (7/8)*(1/7)*(6/6)=1/8 1/8
[QUESTION] What_is_prob_of_picking_2_j,_2_p_and_1_r_when_five_letters_picked_without_replacement_from_jpruqppj?
[TARGET ANSWER] p:3 r:1 q:1 j:2 u:1 3+1+1+2+1=8 (3/8)*(2/7)*(1/6)*(2/5)*(1/4)=1/560 5!/(2!*2!)=30 30*1/560=3/56 3/56
[PREDICTION] p:3 j:2 u:1 r:1 q:1 3+2+1+1+1=8 (3/8)*(2/7)*(1/6)=1/56 3!/(2!)=3 3*1/56=3/56 3/56
By far, the most common questions the network gets correct are ones where the answer is 0 or 1. Perhaps this is not surprising, as recognizing these special cases seems like a fairly easy perception problem e.g. if the letter bag is comprised of a single unique letter (rrrrrrr), then there’s a good chance the answer to this question is 1.
An interesting case is when the network fails to construct the correct intermediate equations, yet by pure coincidence, manages to get the correct answer anyway. As the saying goes, “Even a broken clock is right twice a day”.
Here we see a particular benefit of having the network output intermediate steps instead of a direct answer. The output itself is naturally more interpretable, and we can see whether or not the network truly worked out the correct answer, or stumbled into it by pure coincidence.
Equivalent solutions
Although we use greedy decoding to predict answers, the authors of Deep Learning for Symbolic Mathematics showed that beam search can be used to find a group of equally correct solutions in different forms.
We observe the same phenomenon in our experiments.
[QUESTION] What_is_prob_of_picking_1_d_and_1_i_when_two_letters_picked_without_replacement_from_llddlidddidddldddlld?
[TARGET ANSWER] l:6 i:2 d:12 6+2+12=20 (2/20)*(12/19)=6/95 2!=2 2*6/95=12/95 12/95
[TOP K SEQUENCES]
{'string_tokens': '</s>l:6 d:12 i:2 6+12+2=20 (12/20)*(2/19)=6/95 2!=2 2*6/95=12/95 12/95</s>', 'normlogprob': -1.413268823401162, 'logprob': -7.020529270172119}
{'string_tokens': '</s>l:6 i:2 d:12 6+2+12=20 (2/20)*(12/19)=6/95 2!=2 2*6/95=12/95 12/95</s>', 'normlogprob': -1.4574414982784705, 'logprob': -7.239960670471191}
{'string_tokens': '</s>d:12 l:6 i:2 12+6+2=20 (12/20)*(2/19)=6/95 2!=2 2*6/95=12/95 12/95</s>', 'normlogprob': -1.4709188479375688, 'logprob': -7.306910514831543}
The top 3 answers found by beam search for this particular question have very close log probabilities to each other, and result in the same final answer. The main difference lies in the order of letter counts. It does not matter which letter you count first, as long as you count all of them, so the network simply chooses the order randomly. The top 3 choices end up having the 3 valid variations in letter count order.
Visualizing attention
Another interesting way to interpret what a transformer is doing is by visualizing attention weights. This gives us a glimpse into what the transformer is focusing on at each decoding timestep.


When the bag of letters is given in bracket form “{letter1: count1, letter2: count2, …}”, the network knows to simply copy counts one by one, and attention weights show this clearly.
When the bag of letters is given in scrambled form, the network has to count each one. It seems to do this by grouping same letters together i.e. for each time step, the same letters seem to have the same attention weight magnitude.
Interestingly, for both types of questions, it’s difficult to interpret the attention weights after counting i.e. setting up intermediate steps. This may be because the rest of the intermediate steps depend on copying items from previous output tokens, not the input.
It’s also interesting to see what the network focuses on when giving 1-step answers (0 or 1 probability).

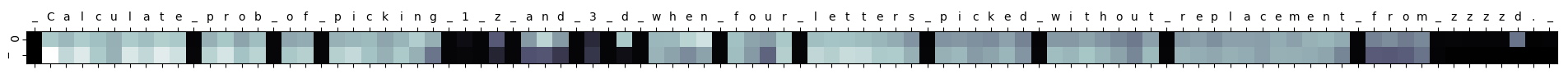


Examining the training data distribution
Something that intrigued me in Saxton et. al.’s paper was how high a baseline transformer scored on probability tasks (~0.77 and ~0.73), given that working these out are a multi-step process. How could basic pattern-matching score so highly on such a task? Is mere perception enough to figure out something like the probability product rule, on such a generic architecture without any prior knowledge of numbers or probability?
To try and explain this, we point out that although questions are unique, a lot of them will share the same answers. For example, Calculate prob of sequence aad from abcda, Calculate prob of sequence bbz from zbbmn, and Calculate prob of sequence rpr from {r: 2, p: 1, x:2} all lead to the same answer, 1/30.
Doing a bit of analysis on training set questions, we find that out of 1 million samples each, swr_p_level_set and swr_p_sequence have 977179 and 978045 unique questions, respectively. This seems reasonable, as duplicates are limited to <3% of the training set and the distribution over questions appears fairly uniform.
On the other hand, doing analysis on training set answers reveals that out of 1 million samples eachs, swr_p_level_set and swr_p_sequence have 1458 and 1865 unique answers, respectively.
Counting the collective number of samples that share the top K most common answers reveals even more imbalance.
For swr_p_level_set:
1000000 samples (100.0%) share 1458 unique answers
750000 samples (75.0%) share top 269 most common answers
500000 samples (50.0%) share top 85 most common answers
250000 samples (25.0%) share top 19 most common answers
For swr_p_sequence:
1000000 samples (100.0%) share 1865 unique answers
750000 samples (75.0%) share top 300 most common answers
500000 samples (50.0%) share top 88 most common answers
250000 samples (25.0%) share top 19 most common answers
Looking at these numbers, the task almost looks like an extremely imbalanced classification problem, where categories are unique probabilities. From this perspective, the high performance of the baseline transformer seems much more reasonable.
For instance, consider questions that “look alike” and have the same final answer: Calculate prob of sequence aad from aadb, Calculate prob of sequence bbz from bbzm. It’s not a stretch to imagine the transformer is simply learning the easy task of recognizing this pattern and spitting out the memorized category/probability (in this case, 1/12), without actually going through the correct intermediate steps. Although speculative, we feel that this sort of shallow reasoning probably makes up a significant chunk of its accuracy.
This also gives an explanation as to why networks, regardless of architecture, consistently score higher on swr_p_level_set than swr_p_sequence, even though swr_p_level_set actually requires more intermediate steps to correctly solve! swr_p_sequence just happens to have more categories/unique answers and the resulting classification task is harder.
It seems unlikely that a transformer trained on this data distribution will capture any sense of the true rules of probability, without more data or some sort of prior or external knowledge. The baseline’s poor performance on the extrapolated set supports this. As soon as a network sees patterns and answers outside what it was trained on, it completely fails, unless it’s something easy to spot from question structure (0 and 1 probabilities).
Related Literature
This work is closely related to another paper by DeepMind, Ling et. al.’s Program Induction by Rationale Generation: Learning to Solve and Explain Algebraic Word Problems. They build a dataset of multiple-choice problems and rationales, which are natural language intermediate steps explaining how to solve the problem. They also train the network to use an external program with instruction primitives like addition and multiplication, and an external memory buffer for storing intermediate results. Ling et. al.’s dataset contains probability problems, harder and more diverse (deck of cards problems) than that available in Mathematics Dataset, however, their results state they are only able to solve simple one or two-step problems. We view being able to solve problems in this dataset as a future goal for the architecture laid out in this article, with the low number and difficulty of obtaining samples (~100k crowdsourced samples) being the main obstacle.
This work is also related to another common theme in automatically solving math problems: converting a word problem into a structured expression that, when evaluated by an external symbolic solver, results in the correct answer (Wang et. al., Roy et. al., Roy and Roth, Kushman, et. al., Hosseini, et. al.).
Do et. al. also attempt to solve Mathematics Dataset using intermediate steps, but they do not report results 8. It seems that it is an unfinished class project.
Limitations and future work
We explored a seq2seq architecture that is able to solve simple probability problems from Mathematics Dataset using intermediate steps and an external symbolic solver. Inference and training with a symbolic solver turns out to be fairly intuitive and easy to integrate into regular seq2seq frameworks.
Although the results are promising, it should be noted that the given task is little more than a toy problem for this approach. Given the low variation of language 9 in Mathematics Dataset, the only notable skills the transformer achieves is counting letters, correctly copying intermediate results, and properly setting up the product rule equation.
The ideal task would leverage the well-documented state-of-the-art language capabilities of the transformer and use it to parse natural language math problems, while a well-tested symbolic solver evaluates intermediate expressions. The main challenge here lies in constructing a dataset with intermediate steps. Generating intermediate steps is relatively easy for fully synthetic datasets such as Mathematics Dataset, but non-trivial for natural language math problems. One way is to use mechanical turking to crowdsource intermediate steps, as done by Ling et. al. for constructing the AQuA dataset.
As shown in this article on a small scale, beam search can find multiple valid ways to come up with the correct answer. An interesting advantage of using crowdsourced intermediate steps is obtaining a variety of intermediate steps for the same types of problems. With enough data, the network could capture the different ways humans solve and approach problems.
The method shown here makes no attempt to generalize to the extrapolated test set, and as a result does not improve upon the baseline. We argue that architectures explicitly designed to perform out-of-distribution generalization (in the same spirit as Trask et. al., Weston et. al., Grefenstette et. al., Graves et. al., Kaiser and Sutskever, Fortunato et. al.) are just as likely to benefit from utilizing an external symbolic solver. Humans generalize, but using a calculator helps them make less mistakes.
Acknowledgments
Experiments were run entirely for free on Google Colaboratory and Paperspace Notebooks. The code is built on top of deepmind/mathematics_dataset for data generation and pytorch/fairseq for seq2seq training.
Code
- For generating train, test, and validation data with intermediate steps - https://github.com/reiinakano/mathematics_dataset/tree/probability-intermediate-steps-2
- For training, evaluating, and visualizing seq2seq models - https://github.com/reiinakano/fairseq/tree/mods
Notebooks for correctly running the above code will be available soon, though more experienced users can probably figure out how things go together.
BONUS: Solving 1 + 1 + 1 + 1 + 1 + 1 + 1
Saxton et. al. observed the curious case that a network could not properly solve 1+1+1...+1 for n>6, even though the train set contained longer sequences and larger numbers.
Naturally, solving expressions in this category would be extremely trivial with a calculator, as the network would only need to correctly copy the expression. We thought it would be a fun demonstration to finally “solve” this problem with the help of a calculator.
Training the network on the add_sub_multiple category, we very quickly achieved 100% on the test set, as the network only needs to correctly copy the expression into the calculator.
Testing this network on 1 + 1 + 1 + 1 + 1 + 1 + 1, here’s what happened:
[QUESTION] 1 + 1 + 1 + 1 + 1 + 1 + 1
[TARGET ANSWER] 1 + 1 + 1 + 1 + 1 + 1 + 1=7 7
[PREDICTION] 1 + 1 + 1 + 1 + 1 + 1 + 1=7 7
Success! The network is able to solve (copy) up to sequences of length 11 with a calculator. Beyond that, we run into the aforementioned out-of-distribution problem, and the network fails to generalize to extrapolated sequence lengths.
-
Usually calculated through something like cross-entropy. ↩
-
For example, if the target sequence is
8 + 7 = 15, the corresponding masked target sequence is8 + 7 = <pad><pad>, where<pad>is a special masking symbol, signifying that these positions are meant to be filled in by an external solver during decoding. ↩ -
This can be implemented in multiple ways. For this article, we use fairseq as our seq2seq training framework.
<pad>symbols in the target sequence, normally used for handling variable-length sequences in a batch, are automatically disregarded by fairseq, so there’s no need to modify the loss function after replacing the target sequence with a masked target sequence. Another way to implement the same functionality is to zero out the loss function at positions occupied by a masking symbol. ↩ -
After all, I do experiments on a single free Google Colaboratory GPU. ↩
-
Saxton et. al. defines two kinds of test sets for each category: an interpolated test set, and an extrapolated test set. The interpolated test set generates samples from the same distribution as the generated training data, with statistical guarantees to ensure questions are mostly distinct between the two datasets. The extrapolated test set aims to measure the ability of a trained network to generalize along different axes outside of its training distribution. For example, the
swr_p_sequence_more_samplesextrapolated test set contains questions that sample more letters than those seen in the training set. ↩ -
The output token with the highest probability is chosen at each decoding time step. This is in contrast to methods such as beam search. ↩
-
Saxton et. al.’s baseline does not show explicit scores per category, only a bar graph. These scores were obtained by estimating the value from the bar graph. ↩
-
In their words, they are “unable to properly decode” their own data files, so they cannot provide results. I include this reference for thoroughness. ↩
-
In fact, this was a deliberate choice by Saxton et. al., as their stated goal was to separate mathematical reasoning from language understanding. ↩